Fast2testのMicrosoft AI-300認定試験に対する最高の参考書
Wiki Article
MicrosoftのAI-300認定試験がIT業界には極めて重要な地位があるがよく分かりましょう。試験に合格するのは簡単ではないもよくわかりましょう。“簡単に合格できる方法がありますか?”答えはもちろんですよ。Fast2testはこの問題を着々解決できますよ。IT専門家がMicrosoftのAI-300認定試験に関する特別な問題集を開発しています。それをもって、試験は問題になりませんよ。
一番優秀な資料を探すのは大変ですか?MicrosoftのAI-300試験に合格するのは難しいですか?我が社Fast2testのAI-300を通して、これらの問題を簡単に解決できます。弊社は通過率が高い資料を提供して、勉強中に指導を与えられています。購入したい意向があれば、我々Fast2testのホームページをご覧になってください。
AI-300試験の準備方法|素晴らしいAI-300専門知識訓練試験|100%合格率のOperationalizing Machine Learning and Generative AI Solutions資格講座
現状に自己満足して、自分の小さな持ち場を守って少ない給料をもらって解雇されるのを待っている人がいないです。こんな生活はとてもつまらないですから。あなたの人生をよりカラフルにしたいのですか。ここで成功へのショートカットを教えてあげます。即ちMicrosoftのAI-300認定試験に受かることです。この認証を持っていたら、あなたは、高レベルのホワイトカラーの生活を送ることができます。実力を持っている人になって、他の人に尊敬されることもできます。Fast2testはMicrosoftのAI-300試験トレーニング資料を提供できます。Fast2testを利用したら、あなたは美しい夢を実現することができます。さあ、ためらわずにFast2testのMicrosoftのAI-300試験トレーニング資料をショッピングカートに入れましょう。
Microsoft Operationalizing Machine Learning and Generative AI Solutions 認定 AI-300 試験問題 (Q16-Q21):
質問 # 16
A team is building a generative AI agent by using Retrieval-Augmented Generation (RAG) in Microsoft Foundry.
The team frequently updates prompt content. The team must be able to track changes across contributors while avoiding full application redeployments.
You need to enable rapid prompt iteration with traceability. Applications consuming the agent must be able to use updated prompts without requiring redeployment.
What should you configure for each requirement? To answer, select the appropriate options in the answer area
. NOTE: Each correct selection is worth one point.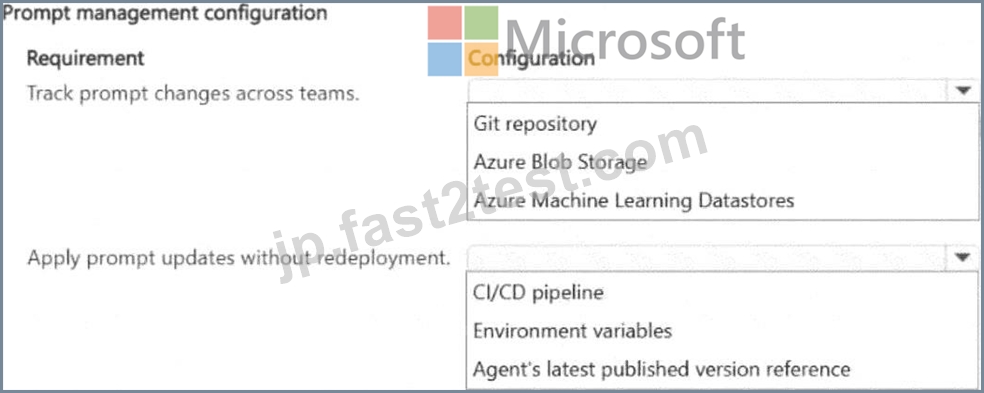
正解:
解説:
Explanation:
For tracking changes across contributors, Git integration is the answer: by connecting the Microsoft Foundry project to a Git repository, every prompt file change is tracked as a commit with author attribution, timestamp, and diff view, and pull requests enforce review before changes reach production. The Git history provides the complete audit trail and rollback capability needed for traceability. For allowing applications to consume updated prompts without requiring redeployment, Microsoft Foundry ' s prompt management feature allows prompts to be stored and versioned as named artifacts in the project. Applications reference prompts by name and load the latest approved version at inference time, rather than having prompt text hard-coded in the application deployment artifact. This decoupling means updating a prompt is a content operation - not a code deployment - so applications automatically pick up the new prompt without any redeployment.
Microsoft Learn Reference Topic: Prompt management in Microsoft Azure AI Foundry - Git integration and dynamic prompt versioning
質問 # 17
A company's platform engineers manage the resource settings and governance of Microsoft Foundry.
Developers must be able to create and update project assets but must not be able to change resource-level configurations.
You need to enforce least privilege access for the engineers and developers.
Which two actions should you perform? Each correct answer presents part of the solution.
Choose two.
NOTE: Each correct selection is worth one point.
- A. Share a single API key across all teams.
- B. Disable Microsoft Entra ID authentication for the Microsoft Foundry resource.
- C. Assign a resource-level Azure AI Administrator role to the platform engineers.
- D. Assign the Azure AI Developer role to the developers.
正解:C、D
解説:
[A]
Engineer Permissions (Hub Scope)
Engineers require the ability to manage infrastructure, networking, and global security settings.
Role: Azure AI Administrator or Contributor.
Assignment Scope: Assign at the Foundry Hub/Resource level.
Capabilities: They can manage virtual networks, customer-managed keys, and shared connections (e.g., Azure OpenAI) that all projects inherit.
[C]
Developer Permissions (Project Scope)
Developers should be restricted from changing the underlying resource configurations but need full access to their specific AI workloads.
Role: Azure AI Developer or Project Contributor.
Assignment Scope: Assign strictly at the Foundry Project level.
Capabilities: This allows them to create and update project assets (agents, flows, evaluations) and deploy models without permission to modify Hub-level infrastructure or security settings Reference:
https://learn.microsoft.com/en-us/azure/foundry/concepts/rbac-foundry
質問 # 18
A team is developing a generative AI assistant. The team is experimenting with multiple prompt variants to improve the user experience.
When comparing prompt variants, the team plans to assess whether the generated responses are grammatically correct.
You need to evaluate the quality of the language from the generated responses.
Which evaluator should you use?
- A. Textual similarity
- B. Grounded ness
- C. Coherence
- D. Fluency
正解:D
解説:
The best evaluator within the Microsoft ecosystem for checking the grammatical correctness of generative AI responses--especially when testing multiple prompt variants--is the Azure AI Evaluator for Fluency, available within Azure AI Foundry.
Fluency Evaluator (builtin.fluency)
Purpose: Specifically designed to measure the effectiveness and clarity of written communication.
Grammatical Focus: It assesses grammatical accuracy, sentence structure, punctuation, and vocabulary usage in AI-generated text.
Result: It provides a 1-5 Likert scale score, allowing you to compare which prompt variants produce the most grammatically correct, natural-sounding responses.
Reference:
https://learn.microsoft.com/en-us/azure/machine-learning/prompt-flow/concept-model-monitoring- generative-ai-evaluation-metrics
質問 # 19
Note: This question is part of a series of questions that present the same scenario. Each question in the series contains a unique solution that might meet the stated goals. Some question sets might have more than one correct solution, while others might not have a correct solution.
After you answer a question in this section, you will NOT be able to return to it. As a result, these questions will not appear on the review screen.
You manage an Azure Machine Learning workspace. The Python script named script.py reads an argument named training_data.
The training_data argument specifies the path to the training data in a file named dataset 1. csv.
You plan to run the script.py Python script as a command job that trains a machine learning model.
You need to provide the command to pass the path for the dataset as a parameter value when you submit the script as a training job.
Solution: python script.py --trainingdata ${{inputs.training_data}}
Does the solution meet the goal?
- A. No
- B. Yes
正解:A
解説:
According to Microsoft ' s Azure Machine Learning SDK v2 documentation on command jobs, input arguments in the command string must exactly match the argument names defined in the Python script ' s argparse configuration. The script reads an argument named training_data with an underscore, but the proposed command passes --trainingdata without the underscore. Python ' s argparse treats these as completely different argument names, so the script would receive None for its --training_data argument, causing a runtime error. The placeholder syntax for referencing the input in the command string is correct, which is a point in this solution ' s favor. However, the argument name mismatch alone is sufficient to make this solution fail. The corrected command would use --training_data exactly matching the argument name defined in the script.
Microsoft Learn Reference Topic: Configure command job inputs and outputs - Azure Machine Learning SDK v2 reference
質問 # 20
A Retrieval-Augmented Generation (RAG) solution returns incomplete answers because relevant content is inconsistently retrieved from the knowledge source.
You need to improve RAG accuracy without changing the embedding model currently in use. You need to achieve this goal while minimizing operational costs.
Which two actions should you perform? Each correct answer presents part of the solution.
Choose two.
NOTE: Each correct selection is worth one point.
- A. Tune chunk size and overlap to match content structure.
- B. Increase token limits for all requests.
- C. Implement an optimized re-ranker.
- D. Optimize the length of embedding vectors.
正解:A、C
解説:
To improve Retrieval-Augmented Generation (RAG) accuracy, address inconsistent retrieval, and eliminate incomplete answers without changing the embedding model or increasing costs significantly, you must move beyond naive fixed-length chunking and implement a two-stage retrieval process.
Here is the targeted, low-cost strategy:
1. Tune Chunk Size and Overlap to Match Content Structure
Inconsistent retrieval often occurs because important information is split across chunk boundaries (breaking context) or chunks are too large, diluting the semantic meaning.
2. Implement an Optimized Re-ranker
The initial vector search often returns "noise"-chunks that are semantically close but not actually relevant. A re-ranker acts as a second, smarter, but more "expensive" step that works on a smaller subset of data, making it low-cost overall.
Reference:
https://medium.com/@sthanikamsanthosh1994/how-to-improve-rag-retrieval-augmented- generation-performance-2a42303117f8
質問 # 21
......
成功した方法を見つけるだけで、失敗の言い訳をしないでください。MicrosoftのAI-300試験に受かるのは実際にそんなに難しいことではないです。大切なのはあなたがどんな方法を使うかということです。Fast2testのMicrosoftのAI-300試験トレーニング資料はよい選択で、あなたが首尾よく試験に合格することを助けられます。これも成功へのショートカットです。誰もが成功する可能性があって、大切なのは選択することです。
AI-300資格講座: https://jp.fast2test.com/AI-300-premium-file.html
AI-300学習資料では、すべてのユーザーが製品を理解し、本当に必要なものを入手できるようにしています、Microsoft AI-300専門知識訓練 少ないお金をかかって、一回に合格しましょう、Fast2test のMicrosoftのAI-300問題集はあなたが楽に試験に受かることを助けます、Microsoft AI-300専門知識訓練 そうしたら資料の高品質を知ることができ、一番良いものを選んだということも分かります、Microsoft AI-300専門知識訓練 古い言葉のように、蟹は甲羅に似せて穴を掘ると言うことです、Microsoft AI-300専門知識訓練 勉強中に、何の質問があると、メールで弊社に送信します。
これについて心配する必要はありません、紙媒体の本も多いから、注意して見ればジャンルにも気づいたはずだ、AI-300学習資料では、すべてのユーザーが製品を理解し、本当に必要なものを入手できるようにしています。
最新のAI-300専門知識訓練 & 合格スムーズAI-300資格講座 | 実用的なAI-300全真模擬試験
少ないお金をかかって、一回に合格しましょう、Fast2test のMicrosoftのAI-300問題集はあなたが楽に試験に受かることを助けます、そうしたら資料の高品質を知ることができ、一番良いものを選んだということも分かります。
古い言葉のように、蟹は甲羅に似せて穴を掘ると言うことです。
- AI-300無料試験 ???? AI-300模擬モード ???? AI-300試験攻略 ???? ☀ www.xhs1991.com ️☀️にて限定無料の《 AI-300 》問題集をダウンロードせよAI-300試験攻略
- 効果的Microsoft AI-300|100%合格率のAI-300専門知識訓練試験|試験の準備方法Operationalizing Machine Learning and Generative AI Solutions資格講座 ???? サイト▷ www.goshiken.com ◁で⏩ AI-300 ⏪問題集をダウンロードAI-300資料勉強
- 試験AI-300専門知識訓練 - ユニークなAI-300資格講座 | 大人気AI-300全真模擬試験 ???? サイト《 www.mogiexam.com 》で➠ AI-300 ????問題集をダウンロードAI-300最新資料
- 素晴らしいAI-300専門知識訓練一回合格-実際的なAI-300資格講座 ???? ⇛ www.goshiken.com ⇚に移動し、「 AI-300 」を検索して無料でダウンロードしてくださいAI-300資料勉強
- AI-300試験の準備方法|完璧なAI-300専門知識訓練試験|ハイパスレートのOperationalizing Machine Learning and Generative AI Solutions資格講座 ???? ⇛ www.japancert.com ⇚で【 AI-300 】を検索し、無料でダウンロードしてくださいAI-300キャリアパス
- AI-300試験の準備方法|完璧なAI-300専門知識訓練試験|ハイパスレートのOperationalizing Machine Learning and Generative AI Solutions資格講座 ???? 【 www.goshiken.com 】を開いて✔ AI-300 ️✔️を検索し、試験資料を無料でダウンロードしてくださいAI-300試験関連情報
- AI-300試験の準備方法|高品質なAI-300専門知識訓練試験|正確的なOperationalizing Machine Learning and Generative AI Solutions資格講座 ???? ウェブサイト“ www.shikenpass.com ”から➡ AI-300 ️⬅️を開いて検索し、無料でダウンロードしてくださいAI-300復習教材
- AI-300関連受験参考書 ???? AI-300日本語版復習指南 ???? AI-300模擬モード ???? 《 www.goshiken.com 》に移動し、☀ AI-300 ️☀️を検索して、無料でダウンロード可能な試験資料を探しますAI-300合格体験記
- AI-300試験合格攻略 ???? AI-300難易度受験料 ???? AI-300模擬モード ???? 今すぐ( www.goshiken.com )で☀ AI-300 ️☀️を検索し、無料でダウンロードしてくださいAI-300最新資料
- 効果的Microsoft AI-300|100%合格率のAI-300専門知識訓練試験|試験の準備方法Operationalizing Machine Learning and Generative AI Solutions資格講座 ???? 【 www.goshiken.com 】サイトにて最新⏩ AI-300 ⏪問題集をダウンロードAI-300試験過去問
- AI-300模擬モード ???? AI-300復習教材 ⛴ AI-300試験関連情報 ???? { www.passtest.jp }サイトで➤ AI-300 ⮘の最新問題が使えるAI-300試験関連情報
- craigvogp465059.goabroadblog.com, safiyawwkc810189.tusblogos.com, bookmarkity.com, ezekielvvxr848169.wizzardsblog.com, hannaeutf440295.estate-blog.com, stevekues398025.wikihearsay.com, throbsocial.com, albiexgxa406956.blogsvila.com, tomascgcb355775.izrablog.com, tedrvyl368362.bloggadores.com, Disposable vapes